

How To Create A New Dataframe In Python
15 ways to create a Pandas DataFrame
A learner's reference for different ways of creating a DataFrame with Pandas
![]()
Motivation
While doing EDA (exploratory data analysis) or developing / testing models, it is very common to use the powerful yet elegant pandas DataFrame for storing and manipulating data. And usually, it starts with "creating a dataframe".
I usually encounter the following scenarios while starting some EDA or modeling with pandas:
I need to quickly create a dataframe of a few records to test a code.
I need to load a csv or json file into a dataframe.
I need to read an HTML table into a dataframe from a web page
I need to load json-like records into a dataframe without creating a json file
I need to load csv-like records into a dataframe without creating a csv file
I need to merge two dataframes, vertically or horizontally
I have to transform a column of a dataframe into one-hot columns
Each of these scenarios made me google the syntax or lookup the documentation every single time, until I slowly memorized them with practice of months and years.
Understanding the pain i t took to lookup, I thought a quick lookup sheet for the multiple ways to create a dataframe in pandas may save some time. This may help learners until they become seasoned data analysts or data scientists.
So here are a few ways we can create a dataframe. If anyone reading this finds other elegant ways or methods, please feel free to comment or message me; I would love to add them in this page with your reference.
Using DataFrame constructor pd.DataFrame()
The pandas DataFrame() constructor offers many different ways to create and initialize a dataframe.
- Method 0 — Initialize Blank dataframe and keep adding records. The columns attribute is a list of strings which become columns of the dataframe. DataFrame rows are referenced by the loc method with an index (like lists). For example, the first record in dataframe df will be referenced by df.loc[0], second record by df.loc[1]. A new row at position i can be directly added by setting df.loc[i] = <record attributes as a list>
# method 0 # Initialize a blank dataframe and keep adding df = pd.DataFrame(columns = ['year','make','model']) # Add records to dataframe using the .loc function df.loc[0] = [2014,"toyota","corolla"]
df.loc[1] = [2018,"honda","civic"] df
- Method 1 — using numpy array in the DataFrame constructor. Pass a 2D numpy array — each array is the corresponding row in the dataframe
# Pass a 2D numpy array - each row is the corresponding row required in the dataframe data = np.array([[2014,"toyota","corolla"],
[2018,"honda","civic"],
[2020,"hyndai","accent"],
[2017,"nissan","sentra"]])
# pass column names in the columns parameter
df = pd.DataFrame(data, columns = ['year', 'make','model'])
df

- Method 2 — using dictionary in the DataFrame constructor. Dictionary Keys become Column names in the dataframe. Dictionary values become the values of columns. Column values are combined in a single row according to the order in which they are specified
data = {'year': [2014, 2018,2020,2017],
'make': ["toyota", "honda","hyndai","nissan"],
'model':["corolla", "civic","accent","sentra"]
} # pass column names in the columns parameter
df = pd.DataFrame(data)
df
- Method 3 — using a list of dictionaries in the DataFrame constructor. Each dictionary is a record. Dictionary Keys become Column names in the dataframe. Dictionary values become the values of columns
data = [{'year': 2014, 'make': "toyota", 'model':"corolla"},
{'year': 2018, 'make': "honda", 'model':"civic"},
{'year': 2020, 'make': "hyndai", 'model':"nissan"},
{'year': 2017, 'make': "nissan" ,'model':"sentra"}
]
# pass column names in the columns parameter
df = pd.DataFrame(data)
df
- Method 4 — using dictionary in the from_dict method. Dictionary Keys become Column names in the dataframe. Dictionary values become the vaues of columns. Column values are combined in a single row according to the order in which they are specified.
data = {'year': [2014, 2018,2020,2017],
'make': ["toyota", "honda","hyndai","nissan"],
'model':["corolla", "civic","accent","sentra"]
} # pass column names in the columns parameter
df = pd.DataFrame.from_dict(data)
df

Note: There is a difference between methods 2 and 4 even though both are dictionaries. Using from_dict, we have the ability to chose any column as an index of the dataframe. What if the column names we used above need to be indexes — like a transpose of the earlier data ? Specify orient = "index" and pass column names for the columns generated after the transpose
df = pd.DataFrame.from_dict(data, orient='index',columns=['record1', 'record2', 'record3', 'record4'])
df 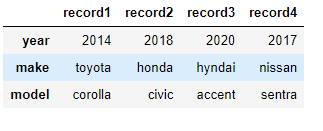
Using pandas library functions — read_csv, read_json
- Method 5 — From a csv file using read_csv method of pandas library. This is one of the most common ways of dataframe creation for EDA. Delimiter (or separator) , header and the choice of index column from the csv file is configurable. By default, separator is comma, header is inferred from first line if found, index column is not taken from the file. Here is how the file looks like:

df = pd.read_csv('data.csv' , sep = ',', header = 'infer', index_col = None)
df
- Method 6 — From a string of csv records using read_csv method of pandas library. This is particularly useful when we dont want to create a file but we have record structures handy- all we do is convert a csv record "string" to a file handle using StringIO library function.
from io import StringIO # f is a file handle created from a csv like string f = StringIO('year,make,model\n2014,toyota,corolla\n2018,honda,civic\n2020,hyndai,accent\n2017,nissan,sentra') df = pd.read_csv(f)
df
- Method 7 — From a json file using read_json method of pandas library when the json file has a record in each line. Setting lines=True mean Read the file as a json object per line. Here is how the json file looks like:

df = pd.read_json('data.json',lines=True)
df
- Method 8 — From a string of json records using read_json method of pandas library. This is particularly useful when we dont want to create a file but we have json record structures handy.
from io import StringIO # f is a file handle created from json like string f = StringIO('{"year": "2014", "make": "toyota", "model": "corolla"}\n{"year": "2018", "make": "honda", "model": "civic"}\n{"year": "2020", "make": "hyndai", "model": "accent"}\n{"year": "2017", "make": "nissan", "model": "sentra"}') df = pd.read_json(f,lines=True)
df
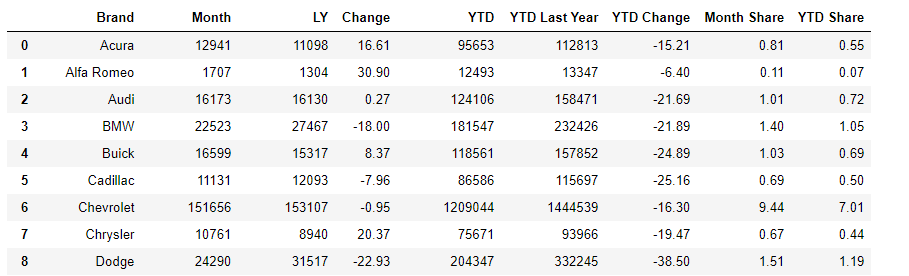
- Method 9 — One of the most interesting ones — read tables from an HTML page using the pandas library built in read_html. This generates a list of dataframes; behind the scenes it scrapes the html page for any <table> tags and tries to capture the table into a dataframe. Even if there is only one table in the page, a list of dataframes is created — so it needs to be accessed using list subscript. The example below shows how to capture an HTML page and then load the tables — this uses the requests library to get the HTML content.
import requestsurl = 'https://www.goodcarbadcar.net/2020-us-vehicle-sales-figures-by-brand'
r = requests.get(url) #if the response status is OK (200)
if r.status_code == 200: # from the response object, pass the response text
# to read_html and get list of tables as list of dataframescar_data_tables = pd.read_html(r.text)
# display the first table
car_data_tables[0]
From other dataframes
- Method 10 — As a copy of another dataframe.
df_copy = df.copy() # copy into a new dataframe object
df_copy = df # make an alias of the dataframe(not creating
# a new dataframe, just a pointer) Note: The two methods shown above are different — the copy() function creates a totally new dataframe object independent of the original one while the variable copy method just creates an alias variable for the original dataframe — no new dataframe object is created. If there is any change to the original dataframe, it is also reflected in the alias as shown below:
# as a new object using .copy() method - new dataframe object created independent of old one a = pd.DataFrame({'year': [2019],'make': ["Mercedes"],'model':["C-Class"]}) b = a.copy() # change old one
a['year'] = 2020 # new copy does not reflect the change
b

# as variable copy - new variable is just an alias to the old one a = pd.DataFrame({'year': [2019],'make': ["Mercedes"],'model':["C-Class"]}) b = a # change old one
a['year'] = 2020 # alias reflects the change
b

- Method 11 — Vertical concatenation — one on top of the other
data1 = [{'year': 2014, 'make': "toyota", 'model':"corolla"},
{'year': 2018, 'make': "honda", 'model':"civic"},
{'year': 2020, 'make': "hyndai", 'model':"nissan"},
{'year': 2017, 'make': "nissan" ,'model':"sentra"}
] df1 = pd.DataFrame(data1) data2 = [{'year': 2019, 'make': "bmw", 'model':"x5"}] df2 = pd.DataFrame(data2) # concatenate vertically
# NOTE: axis = 'index' is same as axis = 0, and is the default
# The two statements below mean the same as the one above df3 = pd.concat([df1,df2], axis = 'index') #OR df3 = pd.concat([df1,df2], axis = 0) # OR df3 = pd.concat([df1,df2]) df3

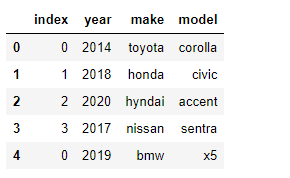
In the above example, the index of the 2nd dataframe is preserved in the concatenated dataframe. To reset the indexes to match with the entire dataframe, use the reset_index() function of the dataframe
df3 = pd.concat([df1,df2]).reset_index() #OR df3 = pd.concat([df1,df2], ignore_index = True)
df3
- Method 12 — Horizontal concatenation — append side by side, not joined by any key
data1 = [{'year': 2014, 'make': "toyota", 'model':"corolla"},
{'year': 2018, 'make': "honda", 'model':"civic"},
{'year': 2020, 'make': "hyndai", 'model':"nissan"},
{'year': 2017, 'make': "nissan" ,'model':"sentra"}
] df1 = pd.DataFrame(data1) data2 = [{'year': 2019, 'make': "bmw", 'model':"x5"}] df2 = pd.DataFrame(data2) df3 = pd.concat([df1,df2], axis = 'columns') #OR df3 = pd.concat([df1,df2], axis = 1) df3
NOTE: For horizontal concatenation,
- The rows of the dataframes are concatenated by order of their position (index)
- If there is any record missing in one of the dataframes, the corresponding records in concatenated dataframe are NaN. This is same as doing a left outer join on index (see merge below)
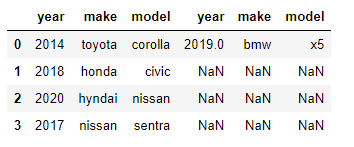
- Method 13 — Horizontal concatenation — equivalent of SQL join.
Inner join
data1 = [{'year': 2014, 'make': "toyota", 'model':"corolla"},
{'year': 2018, 'make': "honda", 'model':"civic"},
{'year': 2020, 'make': "hyndai", 'model':"nissan"},
{'year': 2017, 'make': "nissan" ,'model':"sentra"}
] df1 = pd.DataFrame(data1) data2 = [{'make': 'honda', 'Monthly Sales': 114117},
{'make': 'toyota', 'Monthly Sales': 172370},
{'make': 'hyndai', 'Monthly Sales': 54790}
] df2 = pd.DataFrame(data2) # inner join on 'make'
# default is inner join df3 = pd.merge(df1,df2,how = 'inner',on = ['make'])
df3 = pd.merge(df1,df2,on = ['make']) df3

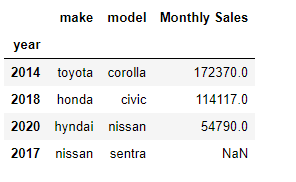
Left join
# for a left join , use how = 'left'
df3 = pd.merge(df1,df2,how = 'left',on = ['make']) df3
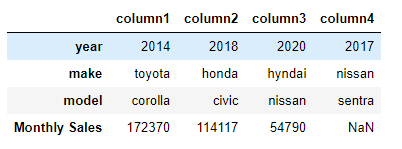
- Method 14 — As a transpose of another dataframe
# To transpose a dataframe - use .T method
df4 = df3.T # To rename columns to anything else after the transpose
df4.columns = (['column1','column2','column3','column4']) df4
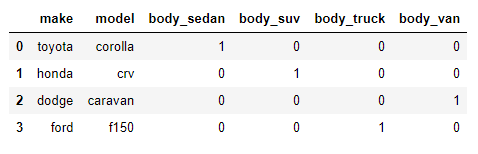
- Method 15 — Conversion to one-hot columns (used for modeling with learning algorithms) using pandas get_dummies function.
One-Hot is basically a conversion of a column value into a set of derived columns like Binary Representation Any one of the one-hot column set is 1 and rest is 0.
If we know that a car has body types = SEDAN, SUV, VAN, TRUCK, then a Toyota corolla with body = 'SEDAN' will become one-hot encoded to
body_SEDAN body_SUV body_VAN body_TRUCK
1 0 0 0 Each one hot column is basically of the format <original_column_name>_<possible_value>
Below is an example:
data1 = [{ 'make': "toyota", 'model':"corolla", 'body':"sedan"},
{'make': "honda", 'model':"crv", 'body':"suv"},
{'make': "dodge", 'model':"caravan", 'body':"van"},
{'make': "ford" ,'model':"f150", 'body':"truck"}
] df1 = pd.DataFrame(data1)df2 = pd.get_dummies(df1,columns = ['body'])
df2
I hope this "cheat-sheet" helps in the initial phases of learning EDA or modeling. For sure, with time and constant practice, all these will be memorized.
All the best then :)
Do share your valuable inputs if you have any other elegant ways of dataframe creation or if there is any new function that can create a dataframe for some specific purpose.
The git link for this notebook is here.
How To Create A New Dataframe In Python
Source: https://towardsdatascience.com/15-ways-to-create-a-pandas-dataframe-754ecc082c17
Posted by: simontonwitedingued.blogspot.com
0 Response to "How To Create A New Dataframe In Python"
Post a Comment